Par jOas,
vendredi, novembre 16 2007.
Assimilation
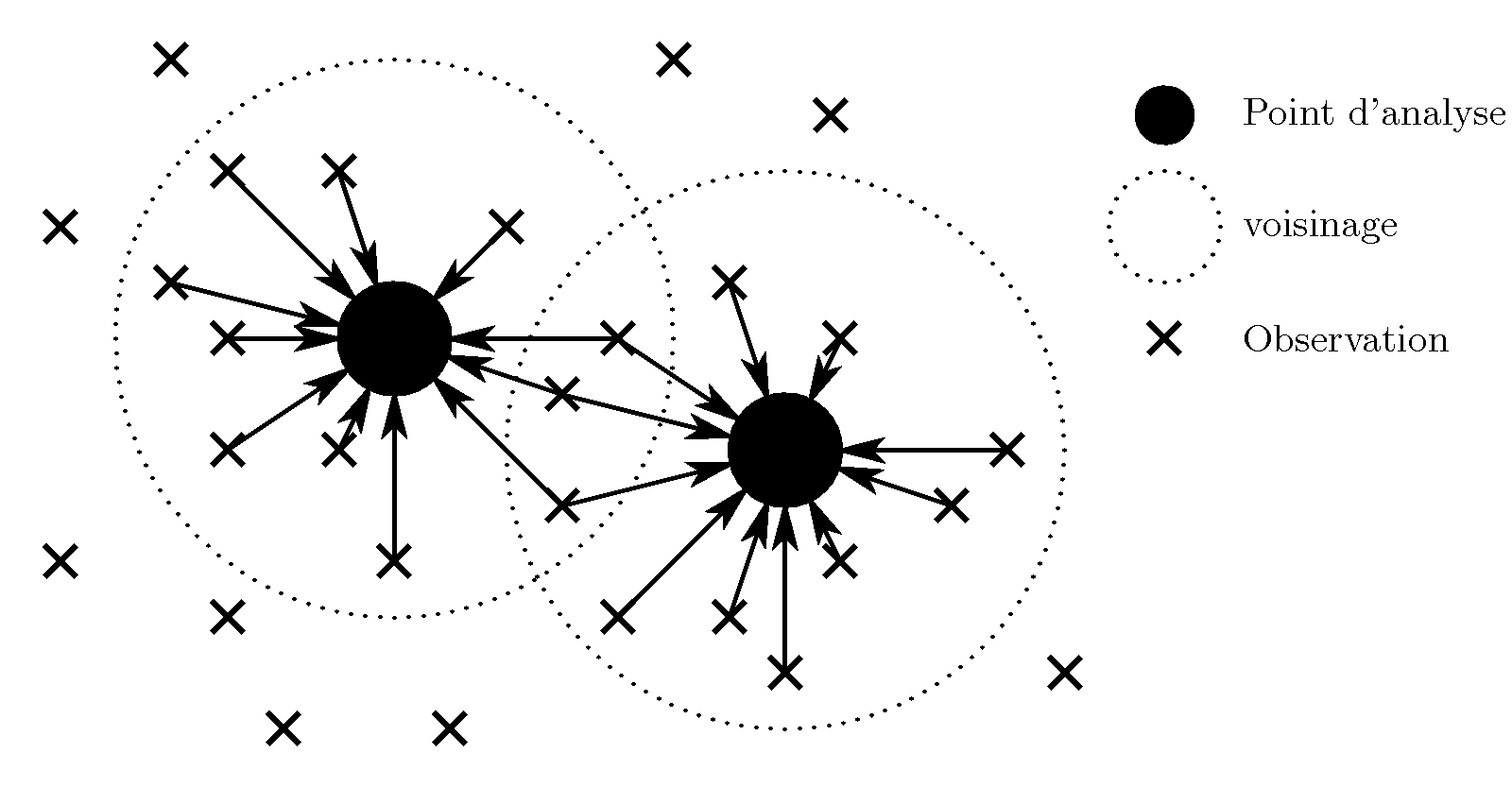
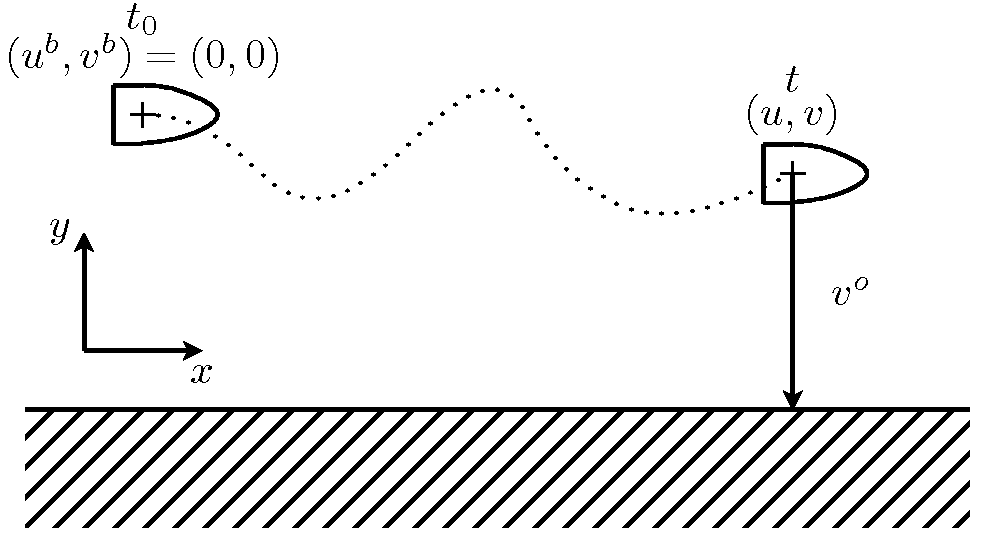
Le 4D-Var est l'extension temporelle du 3D-Var. Cette méthode ne vise pas à obtenir l'état optimal à un instant donné, mais la trajectoire optimale sur une fenêtre de temps donné. Les observations sont donc prises en compte aussi bien dans leur distribution spatiale que temporelle. Cet aspect est déjà pris en compte par le 3D-Var FGAT présenté dans la section ad-hoc. Néanmoins, le 4D-Var apporte un aspect temporel en plus car il propage l'information apportée par les observations à l'instant initial de la fenêtre d'assimilation. De ce fait, l'analyse obtenue doit permettre au modèle d'évolution d'avoir la trajectoire la plus proche possible de l'ensemble des observations utilisées.
Cette amélioration du 3D-Var permet d'ajouter la connaissance de l'évolution du système comme information pour l'analyse.
De nombreuses applications à des modèles réalistes météorologiques (Thépaut et Courtier, 1991 et Zupanski, 1993) et océanographiques (Moore, 1986 ; Shröter etal., 1993 ; Luong etal., 1998 et Greiner etal., 1998) ont depuis longtemps été effectuées.
L'amélioration ainsi apportée, conjuguée au fort développement des moyens de calculs, font que le 4D-Var est venu remplacer le 3D-Var dans les systèmes de prévision opérationnels atmosphériques du CEPMMT en 1997 et de Météo-France en 2000.
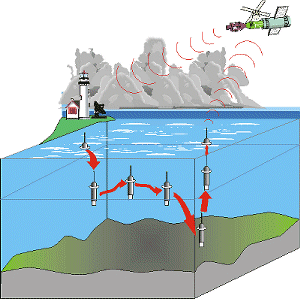 Chose promise, chose due. Alors, voici une vision générale de ce qui occupe les plus longues de mes heures : l'assimilation de données.
Chose promise, chose due. Alors, voici une vision générale de ce qui occupe les plus longues de mes heures : l'assimilation de données.