Le filtre de Kalman d'ensemble reste un filtre Gaussien et n'est pas un filtre particulaire malgré l'emprunt de la nation de particule (comme le filtre SEIK) car il ne gère les statistiques d'erreur que jusqu'à l'ordre deux. Au lieu de propager une matrice de covariance, les erreurs sont représentées statistiquement par un nuage de points propagés par le modèle d'évolution, sans aucune linéarisation. L'étape d'analyse est ensuite celle d'un filtre de Kalman standard.
Comme la montré Burgers etal. (1998),il est essentiel de perturber les observations pour chacun des membres de l'ensemble avec l'estimation de la matrice de covariance d'erreur d'observation \[\mathbf{R}\]. En effet, comme un échantillon statistique a tendance à s'appauvrir par coalescence des points, l'ajout de bruit dans les observations peut être interprété comme l'adjonction d'une partie stochastique permettant d'enrichir l'échantillon.
L'algorithme du filtre de Kalman d'ensemble peut être décrit de la manière suivante (cf. Fig. 1). A partir d'un ensemble de conditions initiales, un ensemble d'états d'ébauche à l'instant \[t_i\] est construit par de courtes intégrations du modèle d'évolution. La matrice de covariance d'erreur de prévision \[\mathbf{P}^f_i\] est calculée à partir de cet échantillon de telle manière que \[\mathbf{P}^f=E\left[(\mathbf{x}^f-\overline{\mathbf{x}}^f)(\mathbf{x}^f-\overline{\mathbf{x}}^f)^T\right]\]. La matrice de gain \[\mathbf{K}\] peut alors être calculée. Chaque ébauche est utilisée pour effectuer une analyse à l'instant \[t_i\] comme décrit par l'Eq. (038}. Les analyses sont obtenues avec des données bruitées. L'ensemble de ces états analysés est ensuite propagé jusqu'à l'instant \[t_{i+1}\] et permet alors d'estimer la matrice \[\mathbf{P}^f_{i+1}\]. Le rang des matrices ainsi estimées est inférieur ou égal à la taille de l'échantillon stochastique, c'est-à-dire très largement inférieur à la taille du vecteur d'état. Cette déficience de rang signifie que l'utilisation directe de la matrice \[\mathbf{P}^f\] dans l'algorithme d'assimilation contraint les corrections identifiées par l'analyse à être définies dans l'espace des membres de l'échantillon. Afin de palier à ce problème, le vecteur d'état \[\mathbf{x}\] peut être séparé en un vecteur \[\mathbf{x}^p\] projeté sur le sous-espace constitué par les échantillons et un vecteur orthogonal. La matrice estimée \[\mathbf{P}^f\] est alors liée dans l'algorithme à \[\mathbf{x}^p\] et une matrice de covariance d'erreur statique est liée au vecteur orthogonal à \[\mathbf{x}^p\]. Outre la conséquente économie de calcul et de stockage par rapport au filtre de Kalman étendu, l'algorithme du filtre de Kalman d'ensemble présente l'avantage d'être particulièrement adapté aux machines de calcul parallèle puisque chaque membre de l'échantillon d'analyse peut être calculé indépendamment des autres, et donc simultanément.
\input{EnKF.pst}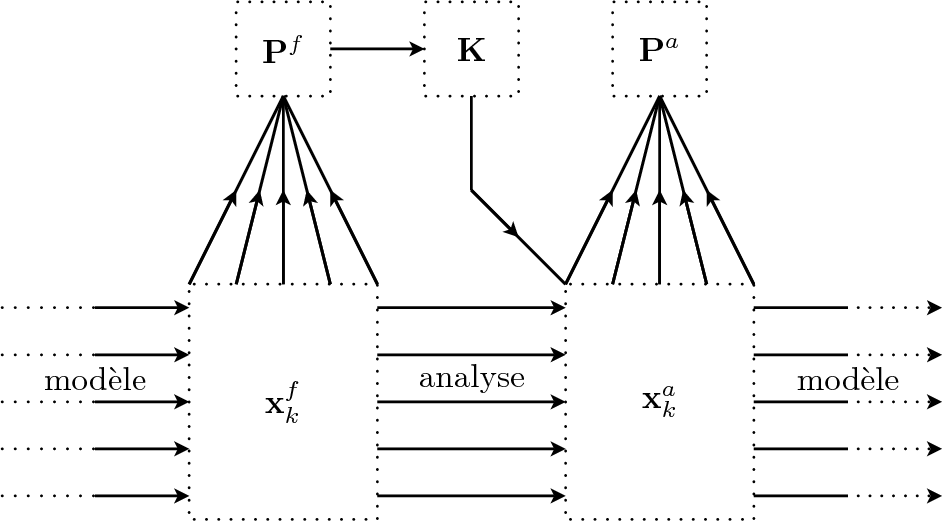
Fig. 1 : Représentation schématique des différentes étapes du filtre filtre de Kalman d'ensemble lors d'un cycle d'assimilation du temps \[t_i\] au temps \[t_{i+1}\]. L'indice \[k\] variant de \[1\] à \[N\] représente les différents membres de l'ensemble.
