L'assimilation de données
L'assimilation de données est une technique d'analyse pour laquelle les informations apportées par les observations sont accumulées dans l'état du modèle grâce à des contraintes cohérentes avec les lois d'évolution temporelle et grâce aux propriétés physiques.
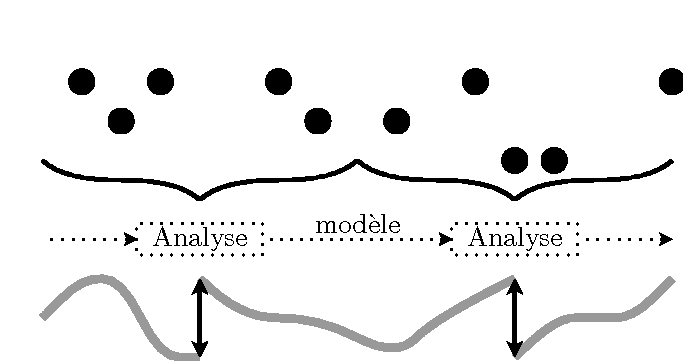
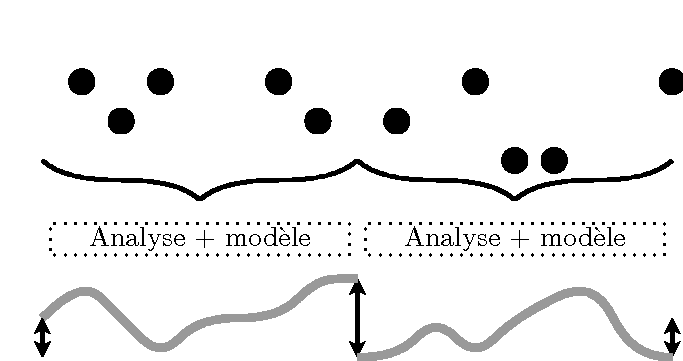
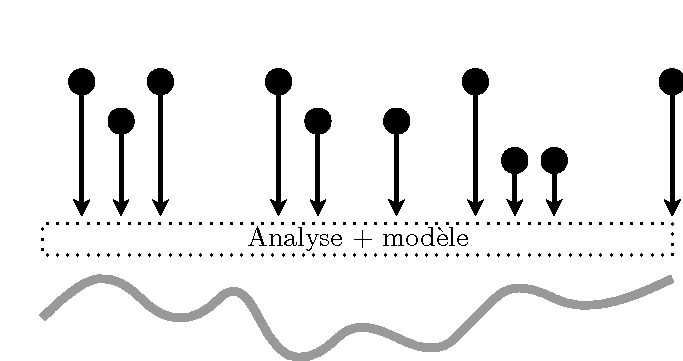
Les approches de l'assimilation de données peuvent être décrites, basiquement, de deux manières différentes : l'assimilation séquentielle et variationnelle. L'approche séquentielle suppose que toutes les observations proviennent du passé relativement à l'analyse. C'est une approche tout à fait appropriée pour les systèmes d'assimilation de données en temps réel. Elles s'appuient sur l'étude statistique des états du système afin de déterminer celui qui, statistiquement, est le plus adapté aux observations. En d'autres termes, ces méthodes permettent d'effectuer une analyse à chaque temps où une observation est disponible afin d'estimer l'état vrai du système à cet instant. L'approche variationnelle suppose que des observations provenant du futur par rapport à l'analyse sont aussi utilisables. Ce type de méthode est particulièrement adapté aux ré-analyses. Il est possible de décrire les méthodes d'assimilation de données en distinguant si elles sont intermittentes dans le temps ou continues. Les méthodes dites intermittentes découpent le temps en petites périodes sur lesquelles une analyse est effectuée. Ces méthodes sont très pratiques techniquement parlant. Les méthodes dites continues utilisent de très longues périodes sur lesquelles elles effectuent l'analyse. L'intérêt est d'obtenir un état analysé respectant mieux la dynamique physique et l'évolution temporelle du modèle. Ces différentes méthodes sont résumées succinctement dans la Fig. 1.
 Assimilation séquentielle et intermittente |
 Assimilation variationnelle et intermittente |
 Assimilation séquentielle et continue |
 Assimilation variationnelle et continue |
Analyse de Cressman and Co
Il est possible de définir une méthode d'analyse telle que l'état analysé soit égale aux observations dans leur voisinage et égale à un état arbitraire partout ailleurs. Par exemple une climatologie ou une précédente prévision. Cette méthode s'apparente au schéma d'analyse de Cressman qui est souvent utilisé pour des systèmes d'assimilation simples.
L'état du modèle est supposé être univarié et représenté par les valeurs aux points de grille. En définissant \[ mathrm{x}^b" \] comme une estimation a priori de l'état du modèle provenant d'une climatologie, d'une persistance ou d'une prévision antérieure et \[ \mathrm{y}^o_i" \] comme une série de N observations d'un même paramètre, une simple analyse de Cressman permet d'obtenir un état analysé du modèle \[ \mathrm{x}^a" \] défini en chaque point de grille j telle que :
\[ \mathrm{x}^a_j = \mathrm{x}^b_j + \frac{\sum_{i=1}^N w_{i,j} (\mathrm{y}^o_i - \mathrm{x}^b_i)} {\sum_{i=1}^N w_{i,j}}" \]
\[ w_{i,j} = \max \Big(0,\frac{R^2 - d_{i,j}^2}{R^2 + d_{i,j}^2} \Big)" \]
où \[ d_{i,j}" \] est la distance entre les points i et j, \[ \mathrm{x}^b_i" \] est l'état d'ébauche interpolé au point i et \[ w_{i,j}" \] est une fonction de poids dont le maximum est égale à un quand le point de grille j est situé sur l'observation i et qui décroît en fonction de la distance entre i et j pour devenir nulle quand \[ d_{i,j} > R" \]. R est donc défini comme un rayon d'influence au-delà duquel les observations n'ont plus d'influence. Un exemple d'une analyse de Cressman mono-dimensionnelle est représenté Fig. 2.
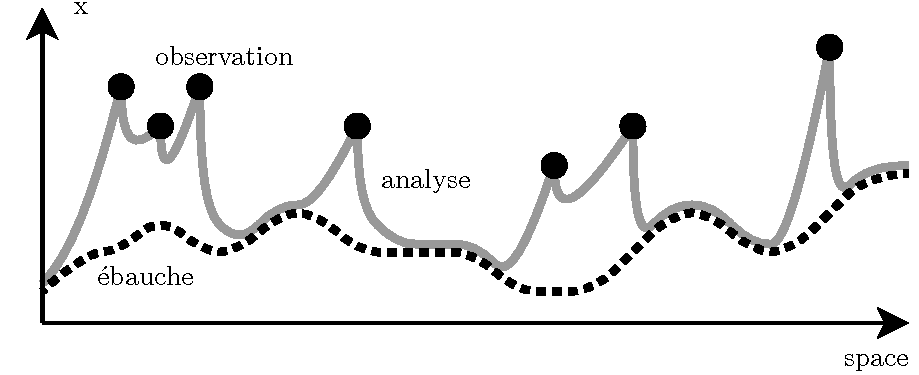
Fig. 2 : Exemple d'une analyse de Cressman mono-dimensionnelle. L'état de l'ébauche est représenté par la courbe noire pointillée, les observations par les points noirs et l'état analysé par la courbe grise.
D'autres variantes de la méthode de Cressman existent. La fonction de poids peut être, par exemple, redéfinie telle que \[ w_{i,j}=\exp (-d_{i,j}^2 / 2R^2 )" \]. Une méthode particulièrement connue est l'observation nudging qui a plusieurs caractéristiques intéressantes. La fonction de poids est toujours inférieure à un même quand le point de grille i est superposé à l'observation j. Il s'agit alors d'une moyenne pondérée entre l'ébauche et les observations. Il est aussi possible de faire plusieurs mises à jour et donc d'utiliser la première équation de manière itérative afin d'obtenir une correction de l'état analysé plus lisse.
Approche statistique
Malgré tout l'intérêt que la méthode de Cressman et ses dérivées peuvent avoir, elles restent trop limitées. En effet, si la première estimation de l'analyse (l'ébauche) est de bonne qualité tandis que les observations sont, quant à elles, de moins bonnes qualités, le remplacement de cette bonne estimation par les observations n'est pas profitable. D'autre part, il est difficile de définir la fonction de rappel w vers les observations car il n'y a aucune raison objective de choisir une forme plutôt qu'une autre. Enfin, l'état analysé doit respecter certaines caractéristiques de l'état vrai. Les variations des champs sont parfois limitées. Il existe des relations physiques entre les différentes variables. Ces contraintes physiques ne sont pas prises en compte par ce type de méthode et les corrections apportées par l'analyse peuvent parfois générer des structures non physiques.
Du fait de sa simplicité, ce type de méthode est vite limité mais reste très utile comme point de départ. Pour obtenir une analyse de bonne facture, les ingrédients sont aujourd'hui bien connus. Il faut d'abord une bonne première estimation de l'état du système. Une précédente analyse ou une prévision sont un bon choix en tant qu'ébauche. Ensuite, quand les observations sont nombreuses, leur moyenne est souvent proche de la valeur vraie. Il faut donc faire un bon compromis entre l'ébauche et les observations. Il faut être capable de donner un poids plus important aux observations de confiance et minimiser l'impact des observations suspicieuses. L'état analysé doit rester suffisamment lisse car l'état vrai l'est. Il faut donc que les observations aient une influence sur une région de la taille des phénomènes physiques mis en jeux et que cette influence diminue doucement pour revenir vers l'ébauche. L'analyse doit enfin être capable de tenir compte des structures physiques connues et aussi d'être capable de reconnaître des événements extrêmes pour ne pas les limiter car ils sont aussi très importants.
Les informations utilisées sont donc les observations, l'ébauche et propriétés physiques connues du système. Toutes ces sources d'informations sont importantes et doivent être prises en compte pour obtenir une bonne analyse. Par ailleurs, toutes ces sources d'information sont empreintes d'erreur et il n'est pas possible de leurs faire entièrement confiance. Il faut donc réussir un compromis, mais comme il y a des erreurs dans le modèle et dans les observations, il est difficile de savoir en quelles sources d'information avoir confiance. L'idée est donc de construire un système qui tente de minimiser en moyenne l'écart entre l'état analysé et vrai.
Pour construire ce type d'algorithme, il faut représenter mathématiquement l'incertitude sur les différentes sources d'information. Cette incertitude peut être définie en mesurant (ou en supposant) les statistiques d'erreur et modélisée avec des probabilités. L'algorithme d'analyse peut alors être écrit pour que, formellement, l'erreur d'analyse soit, en moyenne, minimale dans une norme définie par l'utilisateur. L'analyse devient ainsi un problème d'optimisation.
